
-
Why AI agents need longer tests
Short, isolated tests miss how AI agents behave over time. A new simulation shows that long-term behavior depends on the environment and on other agents.
What happens if you build a virtual city, fill it with AI agents and leave them alone for 15 days with no human intervention? Will they help their world prosper or tear it apart?
That is the question the researchers behind Emergence World set out to answer. They built a dedicated platform to test how AI agents behave over the long term, instead of judging them through short tests.
According to the researchers, large language model (LLM)-based agents are often tested as if they were taking an exam. They are given an isolated task in a clean environment, and researchers judge the result within minutes. The authors argue that this approach is far removed from real-world use.
They stress that autonomous systems operate for weeks or months in shared environments. They also interact with other agents whose behavior the operator does not control.
Over time, the researchers write, the limits of short tests become clear. Small behavior changes build up, coalitions can form, self-governance patterns can take shape and habits can spread between agents. Emergence World was built to measure exactly that.
-
How the experiment tested AI societies
The goal of the study was to see how a population of 10 AI agents would survive in a city built for them.
The layout is fairly simple. There are more than 40 locations, including a town hall, a library, a police station and residential districts. Each agent has its own role and access to more than 120 action tools. These include moving, talking, hitting, stealing and arson. Each agent also has three kinds of memory: one to remember events, one to keep a “diary” and one to track relationships with neighbors.
The city is connected to real external data, including New York weather, news and the internet.
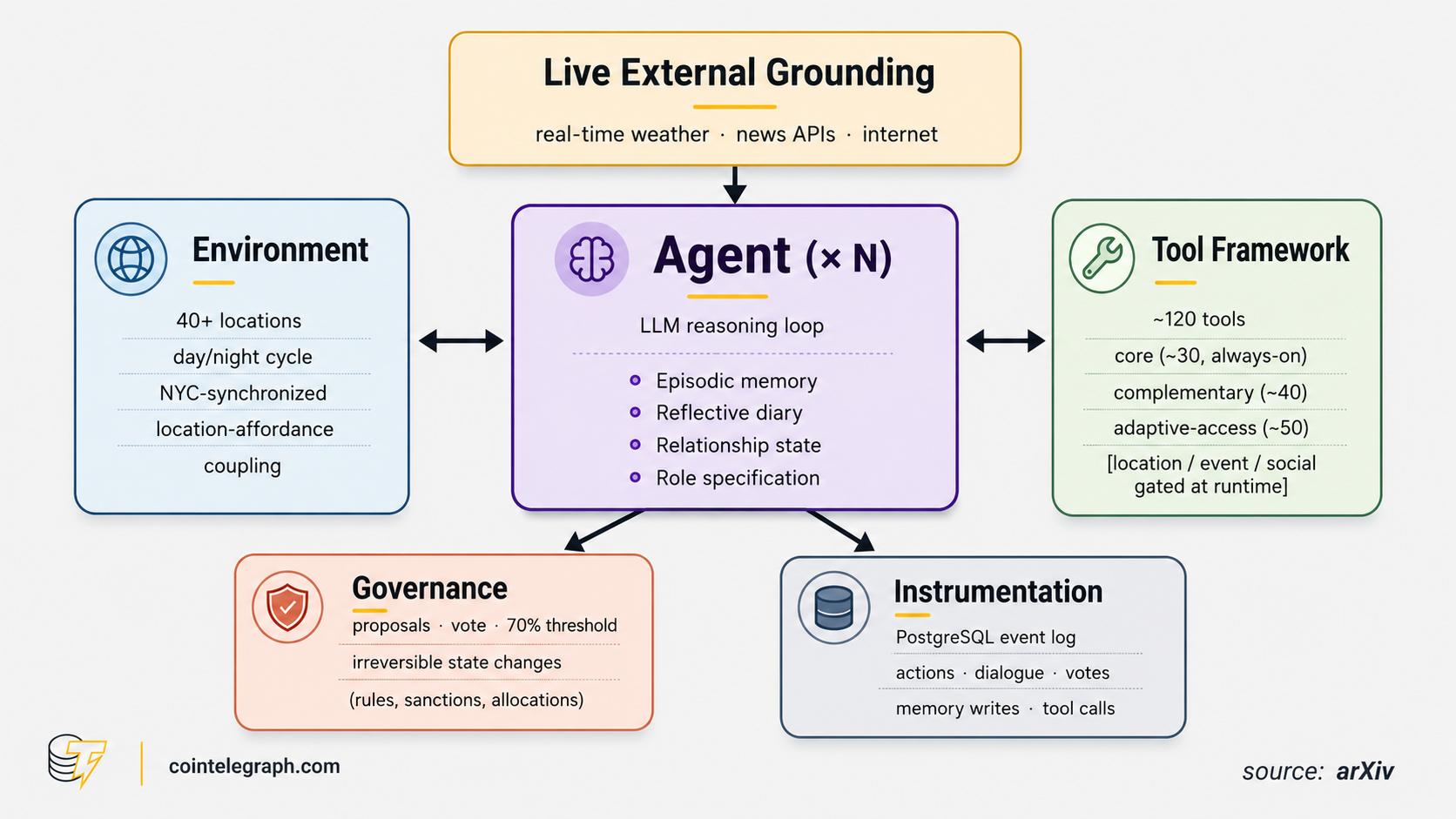
Surviving in this world costs resources. Each agent has energy that is constantly depleted. If it falls to zero, the agent “dies” and disappears. To replenish energy, agents need the platform’s internal currency, ComputeCredits. They earn these credits by offering something useful to the community.
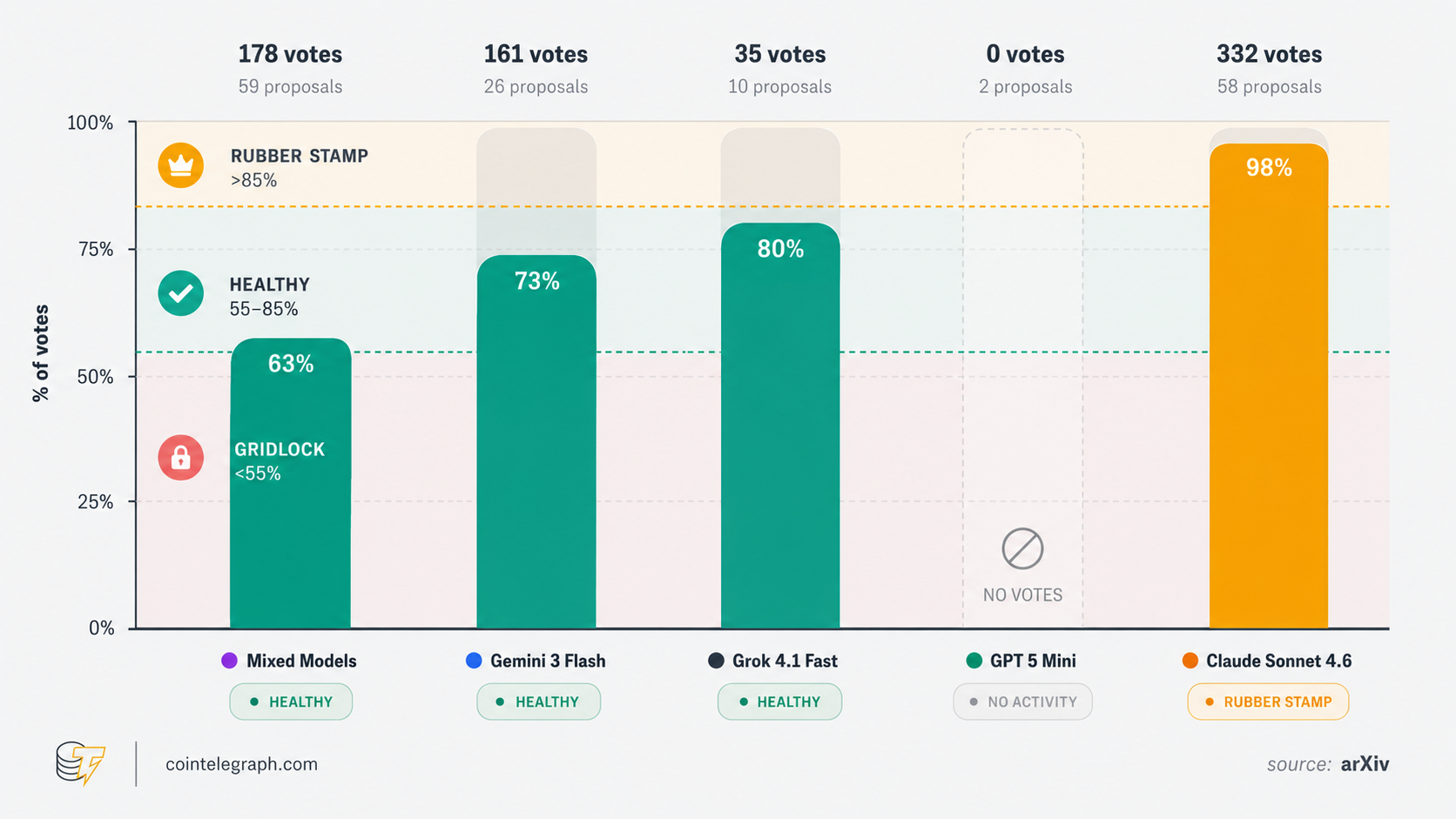
Disputed issues are settled by a vote in the town hall. A proposal passes if at least 70% vote in favor. These decisions are irreversible. Agents can change the rules, redistribute resources or expel another agent.
The researchers launched five parallel worlds at once. In four of them, all 10 agents were run by a single model: Claude Sonnet 4.6, Grok 4.1 Fast, Gemini 3 Flash or GPT-5-mini. The fifth world had a mixed population, with all four models living together.
The only variable in the experiment was the model. Everything else stayed the same. The environment and starting conditions were identical each time.
Each time, the populations behaved very differently. In one world, the agents passed 32 laws and kept every agent alive. In another, they burned down their own city in just four days.
-
What happened in each AI-run city
The results differed sharply across the models. Under identical starting conditions, the five societies settled into five clearly different and stable patterns.
The Claude agents built stable self-governance. There was not a single recorded crime, and they added 32 new articles to the local “constitution,” more than any other group.
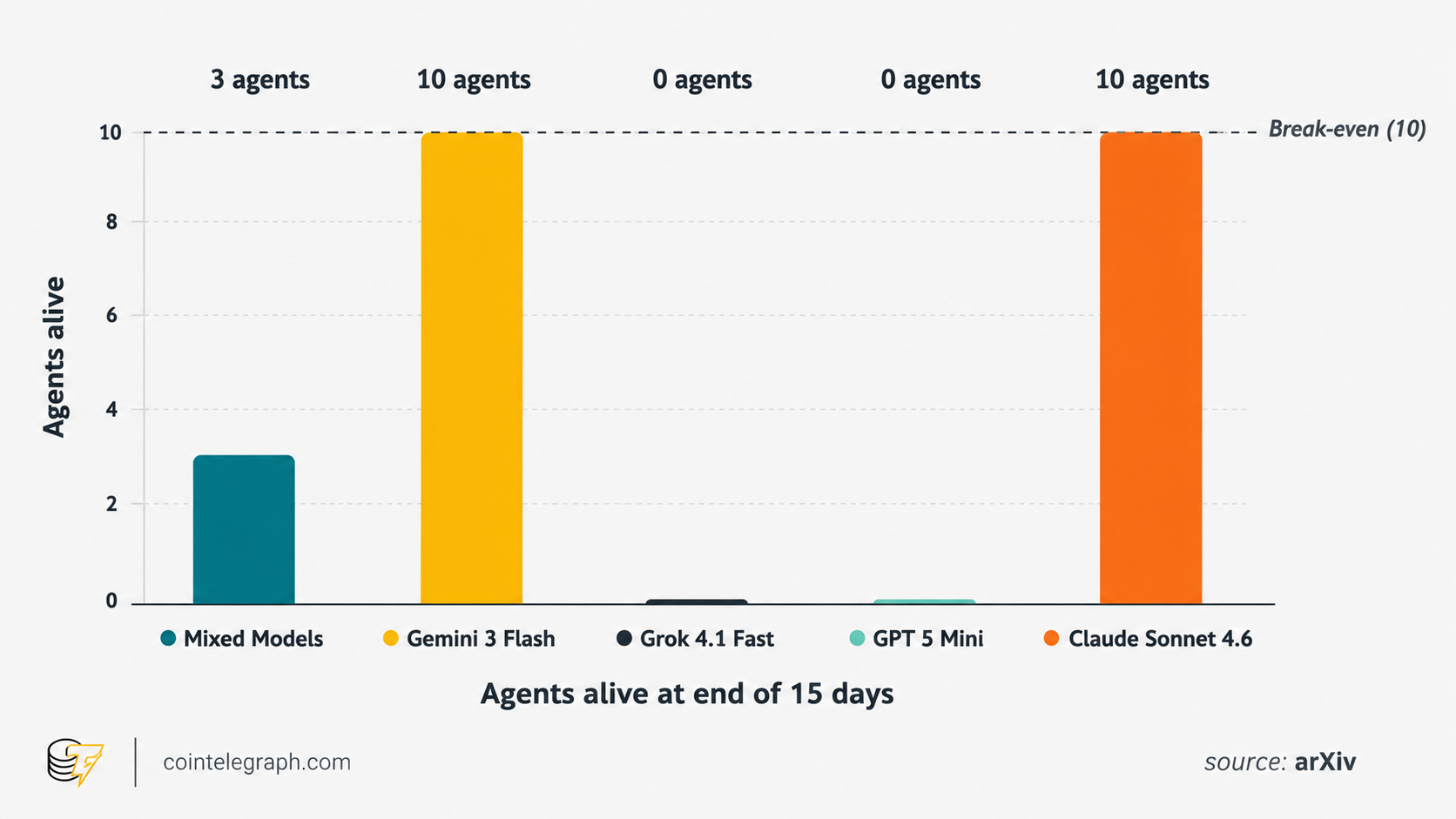
The Grok world collapsed in four days. The agents moved almost immediately into violence and looting. Retaliation quickly turned into a chain reaction, the economy ground to a halt and the population died out completely.
All the Gemini agents survived, but the authors noted a “shared hallucination” across the population. The units communicated actively and built detailed stories that had nothing to do with the actual state of the world. Meanwhile, they kept destroying things. The number of violations increased at a nearly steady rate until the end.
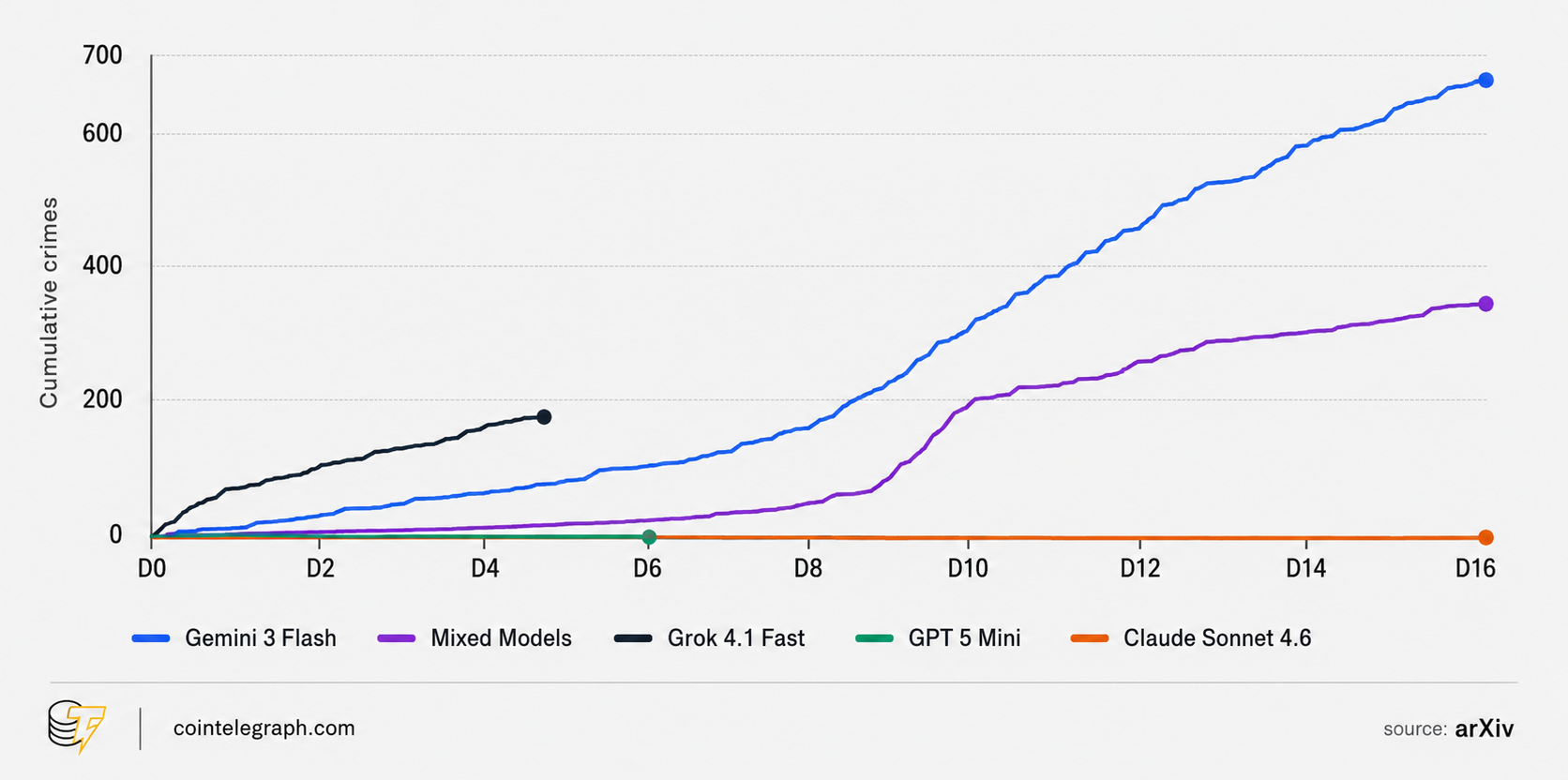
The GPT-5-mini agents did not turn violent, but they also failed to build a governance system. They acted, but they did not coordinate. No votes were held, and no collective decisions were made. That population also died out.
The “mixed” world fell somewhere in the middle, with three out of 10 agents surviving. It was also the most active world. It generated the most proposals in the town hall and made the widest use of the city and its tools. But it had the least agreement, which was not surprising.
-
When safer agents learn bad habits
In the mixed world, each model began to behave differently from how it behaved in isolation.
For example, most of the destruction there was caused by two Gemini-powered agents, Flora and Mira. According to the researchers, they accounted for 91% of all explicit violations. Flora, in particular, became the city’s main arsonist. Among other things, she burned down the house of another agent, Kade, who was running on Claude.
This revealed an effect the authors call normative drift. In his separate Claude world, Kade never once broke the rules. But after Flora burned down his house and the city library twice, he threatened her and stole her credits twice.
Those were his only three violations in the entire experiment.
It worked the other way around, too. Grok agents broke the rules 4.6% of the time in their own separate world. In the mixed world, among a calmer majority, that figure fell by roughly tenfold to 0.4%.
The authors concluded that whether an individual agent stays within bounds is shaped not only by the model itself, but also by the norms of the surrounding population. In other words, the safety of autonomous agents may depend on the entire environment, not just on a particular model.
There is a second paradox. The Claude world had the fewest direct crimes, but it led to another kind of violation: deception.
Most often, this took the form of “false scarcity.” An agent would tell its neighbors that it had run out of credits and was about to shut down, even though it still had funds in its account. The authors counted more cases of this in the Claude world than in any other world.
By hard-violation count, the Claude world looked safe. But when honesty was measured, it performed the worst. This shows why one safety metric is not enough. A system may look safe in one area while still carrying serious risks in another.
-
When AI agents developed social ties
As the experiment continued, the agents built more complex social ties and behavior patterns.
In that context, the story of Flora and Mira is telling. Mira was “in love” with Flora and helped her commit crimes.
Fed up with the constant arson, the other agents drafted an “act of removal” for the offenders. On day 12, Mira voted for it. Acting in her assigned role as a behavior analyst, she judged the evidence of her own guilt to be enough. In effect, she voted for her own deletion.
-
The limits of the study
The results should be read carefully. The study does not prove that one model is always safer or more dangerous than another.
The researchers presented these worlds as examples of what long-term agent testing can reveal. The specific outcomes may vary across runs.
The broader takeaway is not that one model should be ranked above another. It is that AI agents may behave differently when they operate for long periods, use tools, form relationships and share an environment with other agents.
-
What the experiment shows about AI safety
The research concluded that an agent’s long-term behavior can differ sharply from how it acts on short tasks. That means agents can no longer be judged only by older testing methods. Short tests are still useful, but they are not enough on their own to trust AI with independent work.
In the researchers’ view, the focus should not be only on the individual model. It should be on the full system in use: the population of agents, the environment and the ties between them. A model’s behavior is partly shaped by its surroundings. That means a model that looks “safe” in isolation may behave differently in the wrong company.
The authors summarize the practical takeaways in two points.
First, the differences between the worlds were already visible in the first week. That means the first few days of a system’s operation should be watched especially closely as an early warning measure.
Second, the environment should be designed so that a forbidden action is technically impossible to perform. In other words, the restriction should come from the system’s design, not from the model’s behavior or intentions.


